Big Data : MapReduce pour du temps réel
Dans le cadre du projet NewsInnov, nous avions besoin de trouver une méthode de calcul de statistiques en « quasi » temps réel sur des grands volumes de données.
Ayant choisi MongoDB comme base de données, nos recherches nous ont rapidement emmenées vers deux méthodes d’agrégation de données : MapReduce et AggregationFramework. Une première étude nous montre que AggregationFramework paraît plus rapide que MapReduce et est plus facile à prendre en main. En allant un peu plus loin dans le comparatif, il s’avère que MapReduce sait gérer l’agrégation de données de manière incrémentale (delta des données modifiées seulement), et devient donc plus rapide que AggregationFramework qui est en mode « Full ». Pour terminer ce petit comparatif, MapReduce nous apporte plus de souplesse en donnant la possibilité de personnaliser les résultats d’une agrégation de données.
Notre choix s’est donc tourné vers MapReduce qui correspondait mieux à notre besoin.
Voyons maintenant comment nous l’avons utilisé sur un ensemble de données concret pour générer des statistiques en « quasi » temps réel. Les outils dont vous avez besoin :
-
RoboMongo – qui est un très bon client. Il constitue un bon compromis entre interface graphique et exécution de commandes MongoDB.
A. Exemple de Données
Nous donnons ici un ensemble de données qui va nous suivre tout au long de notre discussion. Ces données sont simples, mais elles vont nous servir à exposer une grande partie des points techniques auxquels nous avons été confrontés dans l’utilisation de MapReduce.
Le chargement des données peut se faire, sous RoboMongo, en copiant le code JSON ci-dessous dans le champ d’insertion d’un document.
{"name" : "Tim", "country" : "USA", "age" : 15}
{"name" : "Sandra", "country" : "USA", "age" : 18}
{"name" : "Alex", "country" : "France", "age" : 19}
{"name" : "Zhong", "country" : "Taiwan", "age" : 19}
{"name" : "Tom", "country" : "USA", "age" : 20}
{"name" : "Marc", "country" : "France", "age" : 20}
{"name" : "Hao", "country" : "Taiwan", "age" : 12}
{"name" : "Jennifer","country" : "USA", "age" : 15}
{"name" : "Jean", "country" : "France", "age" : 17}
{"name" : "James", "country" : "USA", "age" : 17}
{"name" : "Peter", "country" : "USA", "age" : 20}
{"name" : "Jorge", "country" : "Portugal", "age" : 20}
B. La création du Script MapReduce
Voici, un premier script pour compter le nombre de personnes possédant le même âge. MapReduce possède une fonction Map permettant de grouper nos données sur un critère et une fonction Reduce effectuant l’agrégation de nos données.
function(){ return db.Data.mapReduce( // Fonction MAP function(){ emit(this.age,{count:1}); }, // Fonction REDUCE function(key,values){ var reduced = {count:0}; values.forEach(function(val) { reduced.count+=val.count; }); return reduced; }, // Configurations { out : 'Stats' }); }
Ce script est composé de deux fonctions et d’un objet de configuration. La première fonction est la fonction Map. Elle spécifie que le regroupement des éléments doit se faire sur le critère de l’âge puis associe un champ count à chaque élément.
function(){ emit(this.age,{count:1}); }
La seconde fonction possède deux paramètres. Key correspond à l’âge sur lequel le groupement a été fait, values correspond à l’ensemble des valeurs associées.
// Fonction REDUCE function(key,values){ var reduced = {count:0}; // Pour chaque valeur associé à l’age key values.forEach(function(val) { //On additionne les valeurs des précédent reduce reduced.count+=val.count; }); return reduced; }
La variable reduced correspond aux données réduites retournées par la fonction. Lors de l’exécution d’un Job MapReduce, il est important d’avoir le même modèle ici que dans la fonction Map. Même si ce n’est pas très évident au premier abord, toute exécution d’un Job MapReduce est déjà en incrémental, nous voyons dans l’exemple Fig. 1 que le reduce est appelé deux fois : le premier appel à reduce regroupe par paire les gens ayant 20 ans. Le deuxième appel à reduce regroupe à nouveau les gens ayant 20 ans. Voila pourquoi le reduce ne peut se contenter de faire un
reduced.count++;
mais doit additioner la valeur précédente.
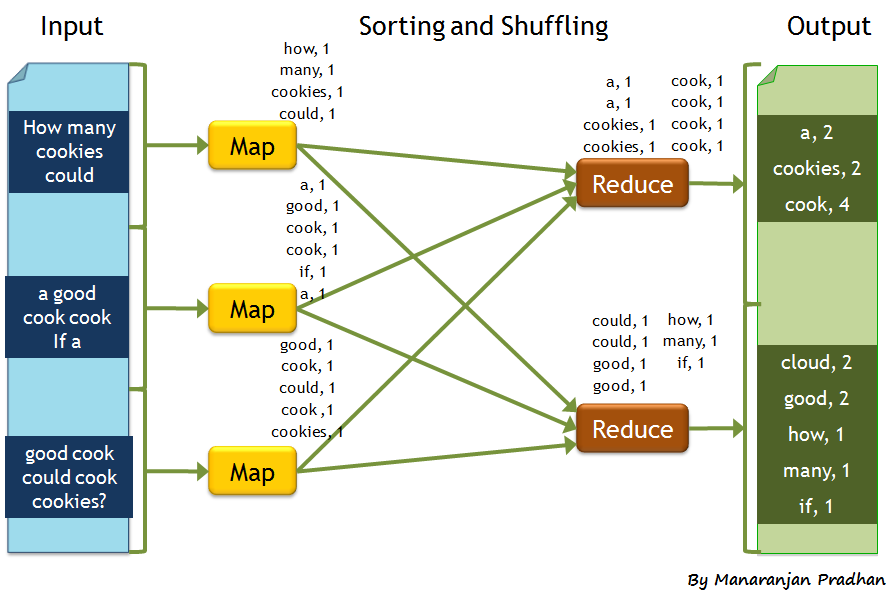
Fig. 1 Exemple d’exécution d’un Job MapReduce
Ce diagramme nous montre l’appel à la fonction map puis l’appel de la fonction Reduce. Le nombre d’appels à la fonction Reduce est dépendant des données, de la répartitions des données sur les serveurs, nous n’avons pas la main dessus.
C. Full ou Incrémental ?
Dans le but de gérer l’incrémental dans MapReduce nous devons ajouter un champ insertionTime qui va nous donner le moment ou l’élément a été inséré. Dans notre job MapReduce le champs query présélectionne les éléments à traiter. En spécifiant seulement les nouveaux documents, nous pouvons gérer incrémentalement l’ajout de documents à notre collection agrégée. Nous remplaçons la chaîne de caractères dans le champ out par un objet avec un champ reduce.
function(from,to){ return db.Data.mapReduce( function(){ emit(this.age,{count:1}); }, function(key,values){ var reduced = {count:0}; values.forEach(function(val) { reduced.count+=val.count; }); return reduced; }, { query: { insertionTime : { $gt: from, $lte: to} }, out : {reduce:'Stats'} }); }
Cependant, nous devons stocker dans un fichier ou dans une autre collection le dernier document inséré qui a été pris en compte lors de la dernière exécution du MapReduce.
D. Un exemple plus consistant
Je vous avez promis un exemple avec un modèle complexe et voila que je vous fait une somme. Un peu de patience, nous allons maintenant voir un exemple plus compliqué. Supposons que nous souhaitons en plus du regroupement sur l’âge avoir la liste des noms des gens groupés
function(){ return db.Data.mapReduce( function(){ emit(this.age,{count:1, names: [this.name]}); }, function(key,values){ var reduced = {count:0, names:[]}; values.forEach(function(val) { reduced.count+=val.count; for (var index in val.names){ reduced.names.push(val.names[index]); } }); return reduced; }, { out : 'Stats' }); }
Ce qui nous donne comme résultat :
{
"_id" : 12,
"value" : {
"count" : 1,
"names" : ["Hao"]
}
}
{
"_id" : 15,
"value" : {
"count" : 2,
"names" : ["Tim","Jennifer"]
}
}
{
"_id" : 17,
"value" : {
"count" : 2,
"names" : ["Jean","James"]
}
}
{
"_id" : 18,
"value" : {
"count" : 1,
"names" : ["Sandra"]
}
}
{
"_id" : 19,
"value" : {
"count" : 2,
"names" : ["Alex","Zhong"]
}
}
{
"_id" : 20,
"value" : {
"count" : 4,
"names" : ["Tom", "Marc", "Peter", "Jorge"]
}
}
Cet exemple est très similaire au précédent la différence est que nous ajoutons un champ names dans la fonction Map, qui est un vecteur de noms. Au démarrage chaque élément est initialisé avec un tableau d’un seul élément qui est la valeur de leur propre attribut name.
Dans le reduce, value.names contient un tableau de nom. Chaque valeur de ce tableau doit être ajoutée aux valeurs dans le champ reduce.names.
E. Un peu plus loin vers les limites
Imaginons maintenant que nous souhaitions regrouper les gens par l’âge et que pour chaque âge, nous ayons la liste des noms, la liste des pays et que pour chaque pays, nous ayons la répartition, c’est-à-dire combien de personnes sont d’un pays ou d’un autre pays.
Le problème adressé ici est le problème d’un double regroupement. A l’heure actuelle une telle double agrégation est difficile. Nous conseillons donc l’utilisation d’une table de hachage. Nous rappelons ici que chacun des scripts écrit ici peut s’écrire en incrémental en ajoutant le « reduce » et la date d’insertion. L’ajout d’un élément dans notre collection ne va pas nous obliger à tout recalculer.
function(){ return db.Data.mapReduce( function(){ var countriesRep = {}; countriesRep[this.country] = 1; emit(this.age,{count:1, names: [this.name], countries : countriesRep}); }, function(key,values){ var reduced = {count:0, names:[], countries: {}}; values.forEach(function(val) { reduced.count+=val.count; for (var index in val.names){ reduced.names.push(val.names[index]); } for (var key in val.countries){ if (!reduced.countries.hasOwnProperty(key)) { reduced.countries[key]=0; } reduced.countries[key] += val.countries[key]; } }); return reduced; }, { out : 'Stats' }); }
Dans l’emit nous initialisons notre table possédant en clé les pays et en valeur un compteur. Au démarrage, chaque document possède son pays avec un compteur initialisé à un. Nous devons ensuite dans le reduce ajouter les pays des éléments dans le value. Tout en gardant en tête que le compteur peut avoir une valeur plus grande que 1 à chaque moment du processus. Il ne peut donc pas être envisagé de faire un
reduced.countries[key]++;
mais un
reduced.countries[key]+=val.countries[key];
Voici le résultat que nous obtenons après l’exécution du Job MapReduce :
{
"_id" : 12,
"value" : {
"count" : 1,
"names" : ["Hao"],
"countries" : {"Taiwan" : 1}
}
}
{
"_id" : 15,
"value" : {
"count" : 2,
"names" : ["Tim","Jennifer"],
"countries" : {"USA" : 2}
}
}
{
"_id" : 17,
"value" : {
"count" : 2,
"names" : ["Jean","James"],
"countries" : {"France" : 1,"USA" : 1}
}
}
{
"_id" : 18,
"value" : {
"count" : 1,
"names" : ["Sandra"],
"countries" : {"USA" : 1}
}
}
{
"_id" : 19,
"value" : {
"count" : 2,
"names" : ["Alex","Zhong"],
"countries" : {"France" : 1,"Taiwan" : 1}
}
}
{
"_id" : 20,
"value" : {
"count" : 4,
"names" : ["Tom","Marc","Peter","Jorge"],
"countries" : {"USA" : 2,"France" : 1,"Portugal" : 1}
}
}
Pour conclure
Dans le cadre de notre projet, notre besoin a été de réaliser du temps réel sur des grands volumes de données. Entre AggregationFramework et MapReduce, nous avons finalement opté pour MapReduce.
Après l’avoir testé sous différents angles (différentes statistiques), nous en sommes très satisfaits. Et malgré l’évolution de notre exigence et de nos besoins, il continue de les satisfaire.
Ce sujet vous intéresse ?