Automatiser la catégorisation des articles de presse grâce à l’apprentissage continu
Le rubricage, ou catégorisation d’articles de presse, consiste à classer les articles en différents groupes thématiques.
Généralement, ce sont les rédactions qui se chargent de leur associer une catégorie. Cette pratique est favorable au référencement naturel, au maillage interne, ainsi qu’à la navigation des lecteurs dans le site web.
Toutefois, la masse de contenu publiée chaque jour sur un site de presse peut rendre difficile la réalisation manuelle de tous les enrichissements sémantiques nécessaires à une bonne indexation, dont le rubricage fait partie. Le risque d’erreur est accru, ce qui peut être dommageable à la visibilité et à la captation de trafic d’un site de presse.
Automatiser le rubricage d’articles de presse grâce à l’apprentissage continu
Aujourd’hui, certains modèles de langage ont la capacité d’automatiser la catégorisation d’articles grâce à une analyse sémantique des contenus.
Cependant, les rubriques sont amenées à évoluer au fil du temps, et de nouvelles catégories peuvent faire leur apparition. Il est donc nécessaire de trouver un moyen pour que le modèle prenne en compte ces évolutions tout en conservant la pertinence de ses prédictions.
Une des solutions pourrait être de réentraîner le modèle sur l’intégralité des données en incluant la nouvelle catégorie : on parle d’apprentissage global. Il est malheureusement très coûteux et chronophage de procéder ainsi.
Une autre solution moins coûteuse serait de faire un apprentissage continu qui consiste en une itération de plus petits entraînements. Chaque entraînement étant constitué du moins de données possible, il est bien moins énergivore que l’apprentissage global.
Pour évaluer l’efficacité des différentes techniques d’apprentissage, il faut commencer par connaître les performances de la méthode d’apprentissage global. Elles constitueront ainsi une référence à laquelle les techniques d’apprentissage continu seront comparées.
Apprentissage global : rubricage d’articles de presse par fine-tuning
Brièvement, le fine-tuning consiste à spécialiser un modèle de langage en le rendant performant sur une tâche spécifique et précise, comme le rubricage d’articles de presse. Bien qu’elle permette d’obtenir de très bons résultats, c’est une technique coûteuse en données et ressources de calcul.
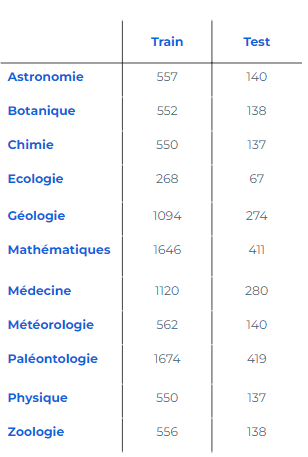
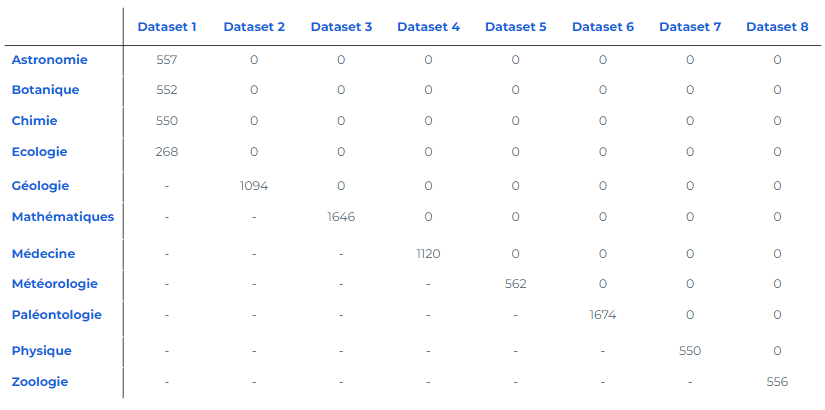
Testons le fine-tuning avec un jeu de données composé de 11 410 articles de presse qui doivent être assignés à une seule des onze catégories existantes ci-dessous.
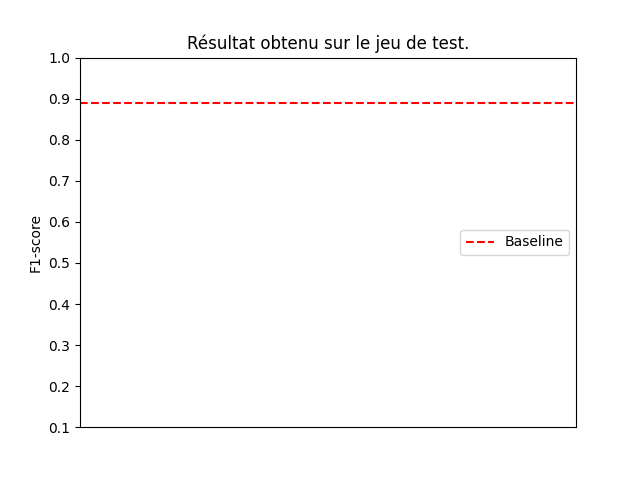
L’entraînement du modèle comprend 80% du jeu de données et les 20% restants ont été utilisés pour le test. Le score obtenu sur le jeu de test est de 0.89.
Finalement, cet apprentissage global est performant, mais il nécessite plusieurs milliers d’articles et de nombreuses ressources de calcul. L’apprentissage continu est une technique moins coûteuse, mais permet-elle d’obtenir d’aussi bons résultats ?
Apprentissage continu : fine-tuning successif et échantillonnage représentatif
Le fine-tuning successif
Le fine-tuning successif consiste à utiliser plusieurs jeux de données différents pour adapter le modèle, notamment en fonction d’une évolution de la ligne éditoriale d’un titre de presse, ou de l’ajout d’une nouvelle catégorie.
Ici, le modèle est déjà entraîné à rubriquer les articles dans “Astronomie”, “Botanique”, “Chimie” et “Ecologie” grâce au premier jeu de données. Le second jeu de données n’est composé que d’articles appartenant à la catégorie “Géologie”. L’objectif est d’ajuster le modèle pour qu’il puisse prédire cette nouvelle catégorie.
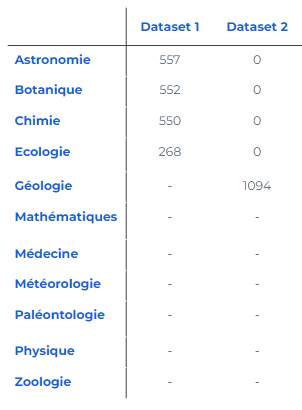
Au fur et à mesure de l’ajout de nouvelles catégories, les jeux de données seront toujours exclusivement constitués d’articles correspondant à la nouvelle rubrique.
Il résulte un score de 0.18 de cette méthode d’apprentissage continu.
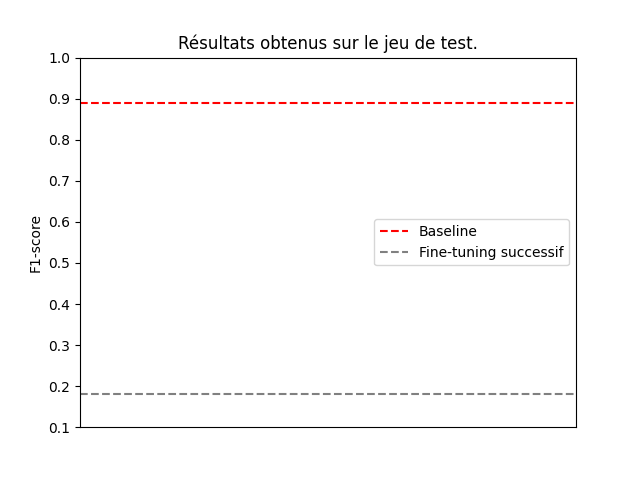
Loin du résultat escompté, cette méthode ne semble pas permettre un rubricage efficace et performant des articles de presse. En effet, il semble que les performances du modèle se dégradent lorsque les nouvelles données d’entraînement ne contiennent pas toutes les possibilités de prédiction : c’est le phénomène d’oubli catastrophique, le modèle a oublié les connaissances qu’il avait au préalable. Il semble donc que des exemples des autres catégories manquent dans le jeu de données.
L’échantillonnage représentatif
L’échantillonnage représentatif requiert d’abord de sélectionner un panel d’articles à inclure dans les jeux de données. Ces derniers doivent être les plus pertinents, afin que le modèle puisse se baser dessus pour les entraînements. L’intérêt de prendre les plus représentatifs est de limiter le nombre d’articles par rubrique déjà apprise, et ainsi d’économiser les coûts et ressources.
Afin d’obtenir le meilleur échantillon possible, il faut calculer les plongements de l’ensemble des articles appartenant à une même catégorie grâce au modèle de langage. En voici une représentation schématique :
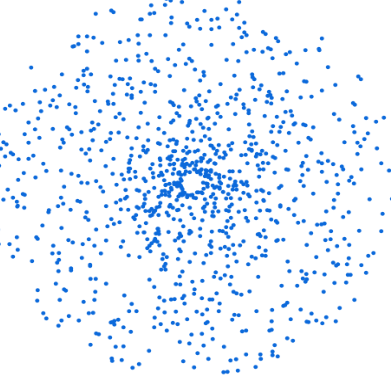
Il faut ensuite calculer le centroïde (en rouge ci-dessous), c’est-à-dire le point moyen sur toutes les dimensions :
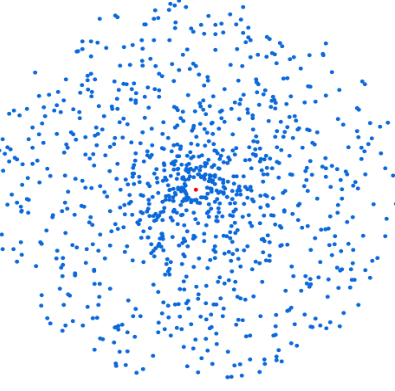
Les K articles les plus proches du centroïde (en bleu cyan ci-dessous) sont identifiés grâce à une similarité cosinus. Ce sont eux qui seront retenus pour faire partie de l’échantillon représentatif :
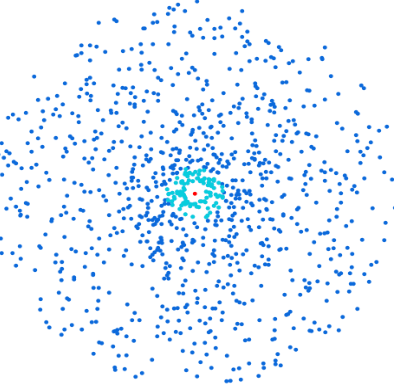
Pour chaque nouvel entraînement, le jeu de données est composé d’un lot d’articles appartenant à la nouvelle catégorie à prédire, ainsi que de l’échantillon des K articles les plus représentatifs issus de chaque catégorie.
Résultat, plus le nombre K est élevé, plus le score de cette méthode d’échantillonnage représentatif augmente jusqu’à atteindre le score de 0.82.
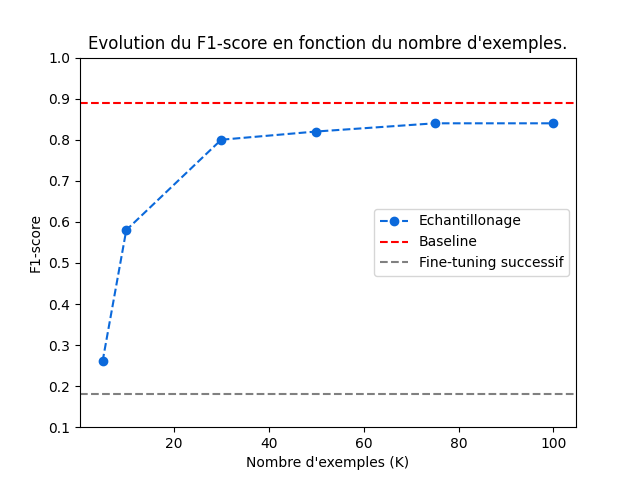
Le score atteint toutefois un pallier d’efficacité autour de 70 articles, ce qui permet de réduire la taille du jeu de données et d’économiser les ressources du modèle ainsi que le temps de traitement nécessaire.
Finalement, bien que l’apprentissage global soit la méthode la plus performante, des techniques moins coûteuses permettent d’atteindre des résultats comparables, à l’image de l’échantillonnage représentatif. De plus, il offre la possibilité d’adapter le modèle en fonction des évolutions de la ligne éditoriale, ou de l’ajout de catégories.
Ce sujet vous intéresse ?